Description
Implement Temporal Fusion Transformer for Transformers for Time Series package, as described in https://arxiv.org/abs/1912.09363
Essentially the TFT is two LSTMs with attention layers after it, with a bunch of skip-connections.
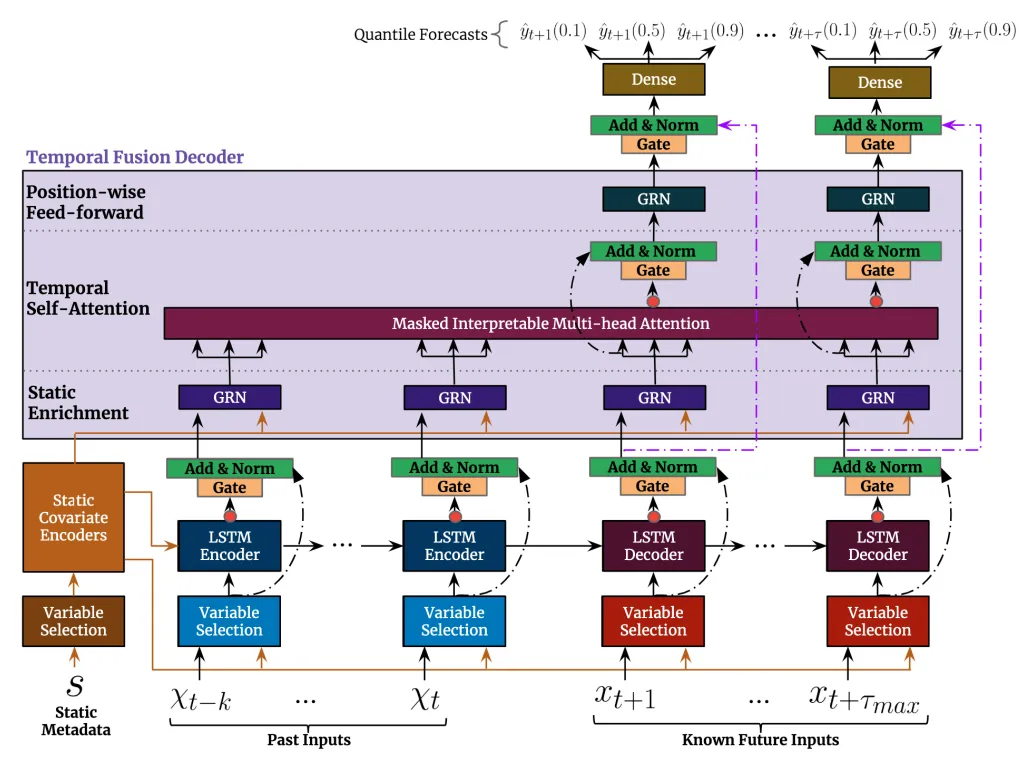
The TFT can take static covariates as input, and in fact work significantly better with static inputs, as they are used to initialize the LSTM hidden and cell states. The Masked Interpretable Multi-head Attention differs from standard multi-head attention in the way that all heads share the same value vector.
Solution
Implemented in https://gitlab.cern.ch/dsb/hysteresis/transformertf/-/commit/9ad607c7730353472d57880cb8e8359839551169