BWXLSTM
ml2 BWXLSTM on with autograd olympus BWXLSTM with autograd
on commit d64e9868a3f134968276a2c5a55de93e8cea7710
config
seed_everything: false
trainer:
accelerator: auto
strategy: auto
devices: auto
max_epochs: 100
min_epochs: 10
inference_mode: false
check_val_every_n_epoch: 1
val_check_interval: 0.05
log_every_n_steps: 10
callbacks:
- class_path: transformertf.callbacks.SetOptimizerLRCallback
init_args: { "on": "step" }
- class_path: transformertf.callbacks.PlotHysteresisCallback
fit:
checkpoint_every:
monitor: "RMSE/validation"
filename: "epoch={epoch}-RMSE={RMSE/validation:.4f}-every"
save_top_k: 0
checkpoint_best:
monitor: "loss/validation"
filename: "epoch={epoch}-RMSE={RMSE/validation:.4f}-best"
save_top_k: 0
lr_scheduler:
class_path: ReduceLROnPlateau
init_args:
monitor: "loss/validation"
patience: 5 # epochs
min_lr: 1e-7
optimizer:
class_path: torch.optim.AdamW
init_args:
lr: 1e-3
weight_decay: 1e-2
model:
class_path: transformertf.models.bwxlstm.BWXLSTM
init_args:
n_layers: 2
n_dim_model: 128
n_dim_fc: 1024
dropout: 0.2
log_grad_norm: false
compile_model: true
optimizer: adamw
weight_decay: 1e-2
sa_optimizer: adamw
sa_lr: 1e-3
lbfgs_start: 50
lbfgs_lr: 1e-1
data:
class_path: transformertf.data.EncoderDecoderDataModule
init_args:
known_covariates:
- I_meas_A_filtered
- I_meas_A_filtered_dot
- B_dot_meas_T_s_filtered
- rdp_mask_eps_1_8e-03
target_covariate: B_meas_T_filtered
time_column: time_ms
time_format: absolute
train_df_paths:
- datasets/train_rdp.parquet
val_df_paths:
- datasets/val_rdp.parquet
normalize: false
ctxt_seq_len: 100
tgt_seq_len: 1200
target_depends_on: I_meas_A_filtered
extra_transforms:
I_meas_A_filtered:
- class_path: transformertf.data.transform.StandardScaler
I_meas_A_filtered_dot:
- class_path: transformertf.data.transform.StandardScaler
B_dot_meas_T_s_filtered:
- class_path: transformertf.data.transform.StandardScaler
B_meas_T_filtered:
- class_path: transformertf.data.transform.DiscreteFunctionTransform
init_args:
xs: "~/cernbox/hysteresis/calibration_fn/SPS_MB_I2B_CALIBRATION_FN_v4.csv"
- class_path: transformertf.data.transform.StandardScaler
batch_size: 64
num_workers: 4
downsample: 1
no_auto_configure_optimizers: false
- TFT nominal training with simulated data on cs-513-ml003
- RMSE 3e-3, SMAPE 2e-2
- TFT hyperparameter scan running with simulated data on cs-ccr-ml004
- Finetune on MBI data
transformertf fit -c tft_mbi.yml -c ~/cernbox/hysteresis/dipole/datasets/train_v2.yml -n mbion cs-513-ml003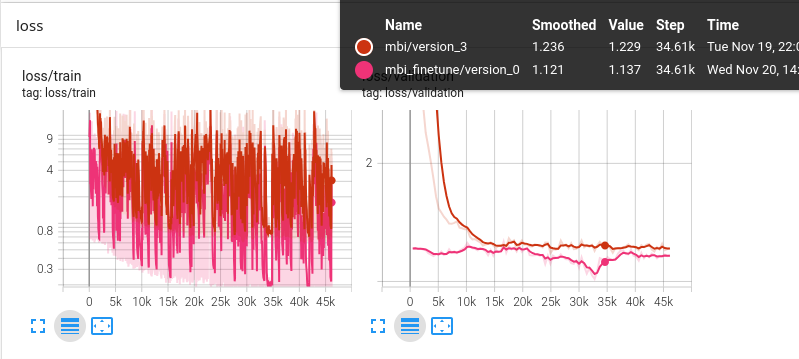
- Loss spikes during training
- TFT finetuning 2